最后留在记忆深处的总是些虚无缥缈的东西,就像你记住一个人往往不是因为她的美,很多年以后你连她的样子都忘记了,可偶然在人流如织的街头闻到她惯用的香水味,你在惊悚中下意识的回过头去,却只看见万千过客的背影。你这才想起即使刚才和你擦肩而过的确实是她,即使你跟她面面相对,你也未必能认出她今天的样子了。
CMS识别方式
页面关键词验证
比如我打开www。langzi。fun这个网站,返回的页面源代码里面有个关键词,根据字典判断是hexo搭建的网站,于是把www。langzi。fun保存在文件夹下的hexo.txt文本中。比如字典
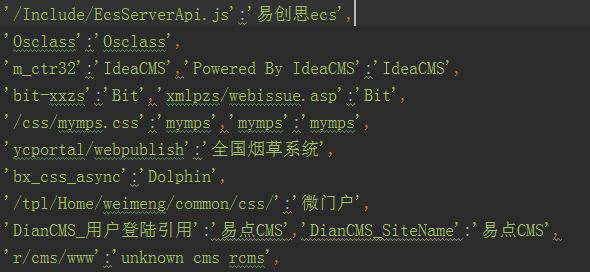
判断键值是否在返回的页面内容中,如果匹配成功则写入本地。
robots.txt文件内容识别
很多网站的robots文件中都有该网站CMS的关键词,所以访问网站的robots文件,寻找返回页面的关键词就可以了。
CMS指纹识别
首先添加后缀,然后对比MD5值即可。

使用方法
首先采集几百几千几万个网站,然后保存在一个url.txt文本中。启动主程序,识别出来的网站会自动分别创建该CMS命名的文本中。

